KV Cache: Intuition, Implementation, Production
Every time you use ChatGPT or Claude, you notice it pauses before the first word, then streams fast after. That pause is the KV cache being built. After that, everything is a lookup into that cache, not a full forward pass over the growing sequence. The KV cache is the reason LLMs can generate long responses in real time.
I hit this for real when we were sizing GPU resources for a production LLM endpoint. The hardware cost did not make sense until I understood what was actually living in memory. During inference, two things live there: model parameters and the KV cache of processed tokens. Most explanations skip the second one.
Here it is three ways.
Before you read this
This article assumes you know:
- Autoregressive decoding: language models generate text one token at a time. For instance, to produce token 500, the model runs a forward pass that considers all 499 tokens before it, then picks the next one from a probability distribution. read here
- Attention mechanism: for each token, the model computes three vectors: a Query (what this token is looking for), a Key (what it offers), and a Value (what it contributes if attended to). The attention score between two tokens is the dot product of one's Query and the other's Key. High score means strong relevance, the model pays more attention to that token when deciding what comes next. (article coming soon)
If you already know these, skip ahead.
Level 1: Intuition
Imagine you are reading a book out loud and someone asks "what happened in chapter 3?" You do not reread the whole book. You remember it! You have a mental cache of everything you read so far. When they ask about chapter 3, you look it up in your memory and answer without rereading chapters 1 and 2.
Similarly, in LLM inference, if we naively implemented it, the model would have to reread the entire growing sequence at every step. To generate token 500, it would read tokens 1 through 499 again. To generate token 501, it would read tokens 1 through 500 again. That is a lot of redundant work.
Here is what is actually happens when we talk to an LLM. There are two distinct phases.
1. Prefill: The model reads your full input at once, computing attention keys and values for every input token in parallel. This saturates the GPU, it is the pause before the first word appears.
2. Decode: The model generates one token at a time. Without caching, each step has to recompute keys and values for all previous tokens from scratch. The cost grows with every token generated. Worse, the decode step is not limited by GPU compute, it is limited by memory bandwidth. Moving all those K and V tensors from memory into the GPUs registers costs more than the arithmetic does.
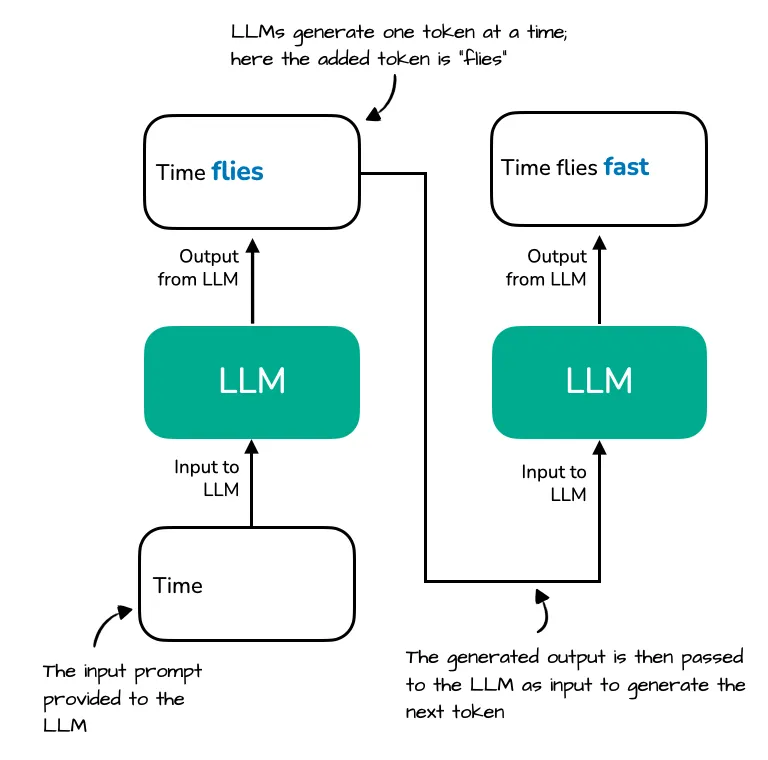 The diagram illustrates how an LLM generates text one token at a time. Starting with the prompt "Time", the model generates the next token "flies." In the next step, the full sequence "Time flies" is reprocessed to generate the token "fast". Source: Sebastian Raschka
The diagram illustrates how an LLM generates text one token at a time. Starting with the prompt "Time", the model generates the next token "flies." In the next step, the full sequence "Time flies" is reprocessed to generate the token "fast". Source: Sebastian Raschka
KV cache is the fix. During prefill, all the key and value tensors get computed and saved. During decode, each new token only computes its own K and V, then attends over the full saved cache. No recomputation. No growing cost.
That is the whole idea.
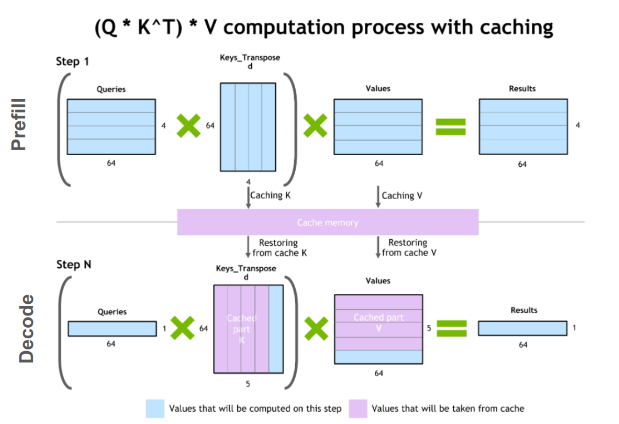 An illustration of the key-value caching mechanism. Source: NVIDIA
An illustration of the key-value caching mechanism. Source: NVIDIA
Without KV cache, real-time token streaming would not exist. You would wait minutes for every response.
Level 2: Implementation
Now let's get into what is actually happening.
How attention works
Transformers use self-attention. For every token, three things get computed:
- Q (Query): what this token is looking for?
- K (Key): what this token offers to others?
- V (Value): what this token actually contributes when attended to?
Attention score between token A and token B is dot product of A's query and B's key. Then you weight B's value by that score and sum everything up.
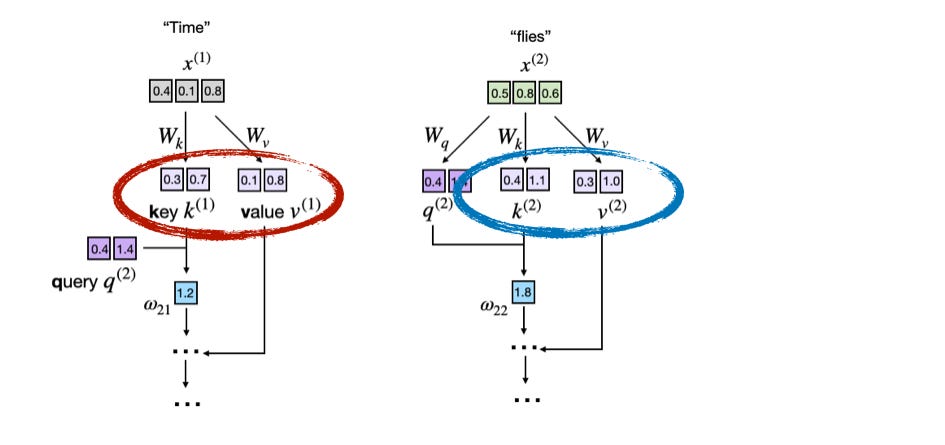 Keys and Values are computed for every token and used by every future token in the sequence. Source: Sebastian Raschka
Keys and Values are computed for every token and used by every future token in the sequence. Source: Sebastian Raschka
When generating token 500, you compute Q for token 500, then dot product with K for tokens 1 through 499, weight V's, sum. That is one forward pass.
For token 501, you do the same but now tokens 1 through 500. You just recomputed K and V for all 500 previous tokens again for no reason. They did not change.
 The highlighted regions are pure repeated work — K and V for every previous token get recomputed at each decoding step. Source: Sebastian Raschka
The highlighted regions are pure repeated work — K and V for every previous token get recomputed at each decoding step. Source: Sebastian Raschka
That is the problem KV cache solves.
The problem in the code
Here is a full, runnable companion notebook. Open in Colab --> and upload notebook from here
https://github.com/bhuvanchennoju/how_ml_actually_works/blob/main/10-kv-cache/kv_cache_implementation.ipynbPyTorch: 2.11.0, SEED=2026
Here is standard single-head causal self-attention. The Head class is the same pattern used in GPT-2, this is real transformer code.
class Head(nn.Module):
"""Single-head causal self-attention. Standard. No caching.
more details here:
https://github.com/bhuvanchennoju/GPT-from-scratch/blob/master/src/multiheaded_attention_bigram/model.py
"""
def __init__(self, n_embed, head_size, block_size, dropout=0.0):
super().__init__()
self.key = nn.Linear(n_embed, head_size, bias=False)
self.query = nn.Linear(n_embed, head_size, bias=False)
self.value = nn.Linear(n_embed, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
# These three lines are the problem.
# K, Q, V get computed for ALL T tokens, every single time forward() is called.
k = self.key(x) # (B, T,head_size)
q = self.query(x)# (B, T,head_size)
v = self.value(x)# (B, T,head_size)
wei = q @ k.transpose(-2, -1) * C**(-0.5) # (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
wei = self.dropout(wei)
return wei @ v # (B, T, head_size)The problem is in those three lines at the top of forward. k and v are computed for every token in x, the full sequence, at every forward pass. Generate 200 tokens and you have run this 200 times, each time over a longer input.
The fix is three lines
class HeadWithCache(nn.Module):
"""Same as Head — with KV cache added in 3 lines."""
def __init__(self, n_embed, head_size, block_size, dropout=0.0):
super().__init__()
self.key = nn.Linear(n_embed, head_size, bias=False)
self.query = nn.Linear(n_embed, head_size, bias=False)
self.value = nn.Linear(n_embed, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x, past_kv=None): # accept cached K, V
B, T, C = x.shape
k = self.key(x)# only for the NEW tokens in x
q = self.query(x)
v = self.value(x)
if past_kv is not None: #prepend past K, V
k = torch.cat([past_kv[0], k], dim=1)
v = torch.cat([past_kv[1], v], dim=1)
T_full = k.shape[1]
wei = q @ k.transpose(-2, -1) * C**(-0.5)
if T > 1: # prefill: apply causal mask; decode (T=1): new token sees all past
wei = wei.masked_fill(self.tril[:T, :T_full] == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
wei = self.dropout(wei)
out = wei @ v
return out, (k, v) #return updated cacheThree changes. Nothing else is different.
forwardnow acceptspast_kv, the accumulated K and V from all previous steps.- If the cache exists, prepend it to the newly computed K and V before running attention.
- Return the updated cache alongside the output so the caller can pass it back next step.
During prefill, you pass the full prompt with past_kv=None. The cache is built from scratch.
During decode, you pass one token at a time. The cache grows by one row each step. K and V for all previous tokens are never recomputed.
 Left: full recomputation at every step. Right: only the new token's K and V are computed; past K and V come from the cache. Source: Sebastian Raschka
Left: full recomputation at every step. Right: only the new token's K and V are computed; past K and V come from the cache. Source: Sebastian Raschka
Benchmark
print("Benchmark: cached vs no cache:")
print(f" {'seq_len':>8} {'no cache':>12} {'with cache':>12} {'speedup':>10}")
print(" " + "-" * 50)
head_base = Head(n_embed, head_size, block_size)
head_cache = HeadWithCache(n_embed, head_size, block_size)
for seq_len in [50,100,200,500]:
# No cache: full growing sequence at every step
t0 = time.perf_counter()
with torch.no_grad():
for i in range(seq_len):
x = torch.randn(1, i + 1, n_embed)
head_base(x)
no_cache_s = time.perf_counter() - t0
# With cache: prefill once, then one token per step
t0 = time.perf_counter()
with torch.no_grad():
prompt = torch.randn(1, 1, n_embed)
_, past_kv = head_cache(prompt)
for _ in range(seq_len - 1):
tok = torch.randn(1, 1, n_embed)
_, past_kv = head_cache(tok, past_kv=past_kv)
cache_s = time.perf_counter() - t0
print(f" {seq_len:8d} {no_cache_s:10.3f}s {cache_s:10.3f}s {no_cache_s/cache_s:8.1f}x")Benchmark: cached vs no cache:
seq_len no cache with cache speedup
--------------------------------------------------
50 0.005s 0.002s 2.7x
100 0.009s 0.003s 2.9x
200 0.028s 0.007s 4.2x
500 0.164s 0.020s 8.0x
You will see ~ 7.9x speedup even on this small example. On real models at real context lengths the gap is much larger because the no-cache path grows quadratically while the cached path grows linearly.
Level 3: Production Reality
Implementing a KV cache is easy. Running it at scale is where things get interesting.
The memory problem
Every token in the KV cache occupies memory. The cost per token across the full model is:
bytes_per_token = 2 * num_layers * (num_heads * d_head) * bytes_per_elementThe factor of 2 is for K and V. In multi head attention, num_heads x d_head equals hidden_size.
For a 7B model at FP16: 2 x 32 layers x 4096 hidden x 2 bytes ≈ 0.5 MB per token.
That scales across the batch and sequence length:
total_kv_cache = batch_size * sequence_length * bytes_per_token-
For a single user at a 4K context: 1 x 4096 x 0.5 MB ≈ 2 GB , just for the KV cache, before model weights.
-
Now think about a 70B model with a full 64-head MHA, a 64K context window, and 50 concurrent users. You are looking at hundreds of gigabytes.
-
A real Llama 70B uses GQA with 8 KV heads instead of 64, which cuts per-token cost by 8x, but with batch sizes and long contexts, memory pressure is still the central constraint in production LLM serving.
Everything in this section exists because of that number.
How production systems handle this
1. Paged Attention (vLLM)
The biggest insight in LLM serving in recent years. Instead of allocating one big contiguous block of memory per sequence, vLLM breaks the KV cache into fixed-size pages and manages them like a virtual memory system. Pages only get allocated when needed. Multiple sequences can share pages for identical prefixes.
 contiguous allocation wastes 60-80% of memory on padding for shorter sequences. Source: Modular
contiguous allocation wastes 60-80% of memory on padding for shorter sequences. Source: Modular
 Pages from different requests interleave freely. No reservation, no fragmentation. Fragmentation drops below 4%. Source: Modular
Pages from different requests interleave freely. No reservation, no fragmentation. Fragmentation drops below 4%. Source: Modular
With this technique, its much better GPU utilization, higher throughput, ability to serve more concurrent users.
2. Quantization
KV cache tensors are stored in FP16 by default. Quantizing to INT8 halves the memory footprint; FP8 is now the production standard, both NVIDIA TensorRT-LLM and vLLM support it natively.
def quantize_cache(tensor: torch.Tensor) -> tuple[torch.Tensor, torch.Tensor]:
"""Quantize a float tensor to INT8 with a single scale factor."""
scale = tensor.abs().max() / 127
quantized = (tensor / scale).round().clamp(-128, 127).to(torch.int8)
return quantized, scale
def dequantize_cache(quantized: torch.Tensor, scale: torch.Tensor) -> torch.Tensor:
"""Recover the float tensor (with some precision loss)."""
return quantized.float() * scale
# 1000 tokens of d_model=512 cache (scaled-down 70B example)
cache_fp32 = torch.randn(1, 1000, 512)
cache_int8, scale = quantize_cache(cache_fp32)
cache_back = dequantize_cache(cache_int8, scale)
fp32_mb = cache_fp32.nelement() * cache_fp32.element_size() / 1e6
int8_mb = cache_int8.nelement() * cache_int8.element_size() / 1e6
max_err = (cache_fp32 - cache_back).abs().max().item()
print(f"FP32 cache size:{fp32_mb:.2f} MB")
print(f"INT8 cache size:{int8_mb:.2f} MB")
print(f"Compression:{fp32_mb / int8_mb:.0f}x")
print(f"Max absolute error: {max_err:.5f}")FP32 cache size:2.05 MB
INT8 cache size:0.51 MB
Compression:4x
Max absolute error: 0.019353. Sliding window / token eviction
For very long contexts you cannot keep everything. StreamingLLM keeps "sink tokens" (the very first few tokens, which are disproportionately attended to) plus a sliding window of recent tokens. H2O and SnapKV are more sophisticated, they score tokens by attention weight and evict the least important ones.
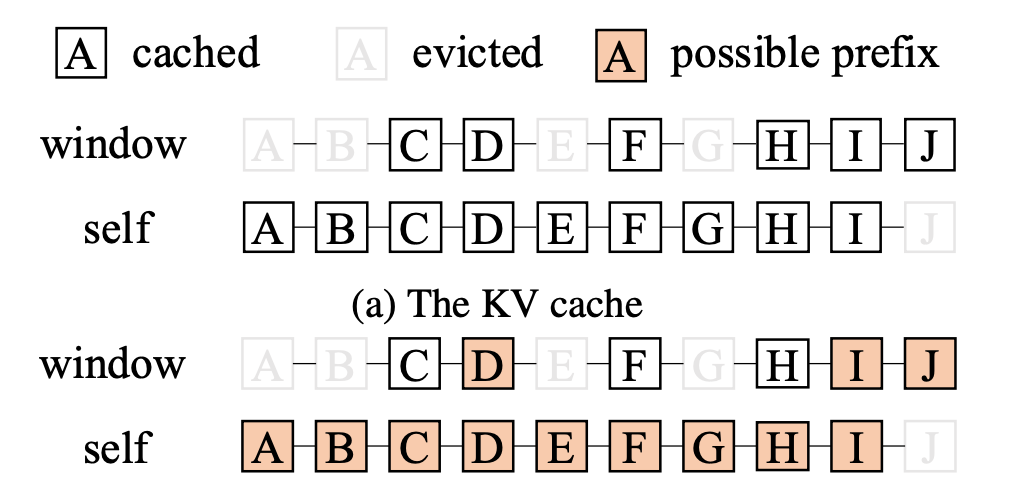 Sink tokens at the start are always kept, evicting them collapses attention. A sliding window covers recent context. Everything in between gets dropped. Source: Modular
Sink tokens at the start are always kept, evicting them collapses attention. A sliding window covers recent context. Everything in between gets dropped. Source: Modular
4. Grouped Query Attention (GQA)
Modern models like Llama 2 70B and Mistral use GQA where multiple query heads share a single K and V head. This directly reduces KV cache size by the grouping factor. If 8 query heads share 1 KV head, you cut your KV cache by 8x at the architecture level.
Tensors are packed as (batch * n_heads, seq_len, d_head),heads live in the batch dimension. Expanding K and V to match Q means repeating along dim=0 (heads), not dim=1 (sequence positions).
def multiheadattention(q: torch.Tensor, k: torch.Tensor, v: torch.Tensor) -> torch.Tensor:
"""Standard scaled dot-product attention."""
scale = math.sqrt(q.shape[-1]) #sqrt of 64--> 8
scores = torch.bmm(q, k.transpose(1, 2)) / scale # q: (B, T_q, D), k: (B, T_kv, D) --> scores: (B, T_q, T_kv);
#(8,20,64) @ (8,64,20) = (8, 20, 20)--> 20 x 20 attention scores per head
return torch.bmm(F.softmax(scores, dim=-1), v) # (B, T_q, T_kv) @ (B, T_kv, D) --> (B, T_q, D);
#(8,20,20) @ (8,20,64) = (8, 20, 64) --> output per head
def grouped_query_attention(q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
n_q_heads: int,
n_kv_heads: int) -> torch.Tensor:
"""GQA: expand K and V along the heads dimension to match Q heads."""
group_size = n_q_heads // n_kv_heads
k = k.repeat_interleave(group_size,dim=0)# (2,20,64)--> (8,20,64) # heads, not sequence
v = v.repeat_interleave(group_size,dim=0)# (2,20,64)--> (8,20,64)
return multiheadattention(q,k,v)
# 4:1 ratio, like Llama 2 70B at smaller scale
batch, seq_len, d_head = 1, 20, 64
n_q_heads, n_kv_heads = 8, 2
q = torch.randn(batch * n_q_heads,seq_len,d_head)# (8, 20, 64)
k = torch.randn(batch * n_kv_heads,seq_len,d_head)# (2, 20, 64) — only 2 KV heads
v = torch.randn(batch * n_kv_heads,seq_len,d_head)# (2, 20, 64)
gqa_ = grouped_query_attention(q, k, v, n_q_heads, n_kv_heads)
print(f"GQA output shape: {gqa_.shape}") #(8, 20, 64)
mha_kv = 2 * n_q_heads * seq_len * d_head
gqa_kv = 2 * n_kv_heads * seq_len * d_head
print(f"\nMHA KV cache elements: {mha_kv:,}")
print(f"GQA KV cache elements: {gqa_kv:,}")
print(f"Reduction: {mha_kv // gqa_kv}x")GQA output shape: torch.Size([8, 20, 64])
MHA KV cache elements: 20,480
GQA KV cache elements: 5,120
Reduction: 4x5. Hybrid architectures
The newest models mix attention layers with state space models like Mamba. Mamba layers use a fixed-size recurrent state instead of growing K/V tensors, O(1) memory regardless of context length. The KV cache only accumulates for the attention layers.
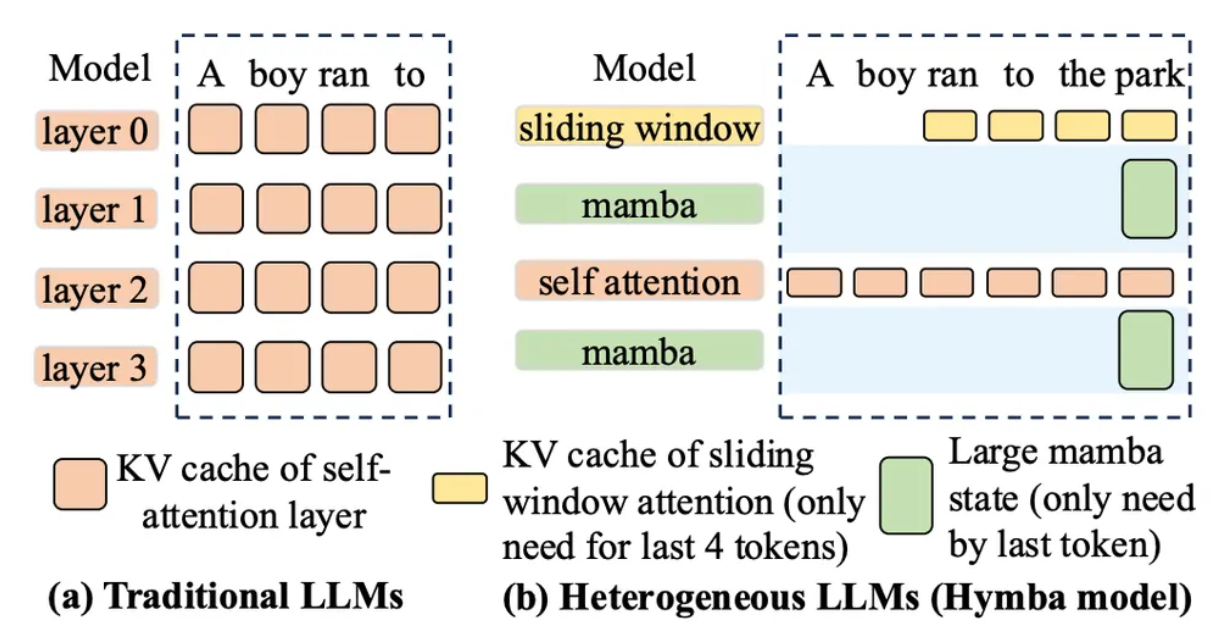 Hybrid architectures reduce total KV cache size because Mamba layers carry no sequence-length-dependent memory. Source: Modular
Hybrid architectures reduce total KV cache size because Mamba layers carry no sequence-length-dependent memory. Source: Modular
Summary:
Intuition:during prefill your model builds a memory of everything it read; during decode it looks things up instead of rereading.
Implementation: pass K and V from previous steps as past_kv; each new token computes its own K and V, prepends the cache, and attends over the full history.
Production: managing that cache without running out of GPU memory is one of the hardest engineering problems in LLM serving right now.
References
- Attention Is All You Need
- vLLM: Efficient Memory Management for LLM Serving
- GQA: Training Generalized Multi-Query Transformer Models
- Sebastian Raschka: Coding the KV Cache in LLMs
- Modular: The Five Eras of KV Cache
- H2O: Heavy-Hitter Oracle for LLM KV Cache
- NVIDIA: Mastering LLM Inference Optimization